
Xinha is a very handy text-editor which can easily be applied on any textarea field. See the following picture for an example:
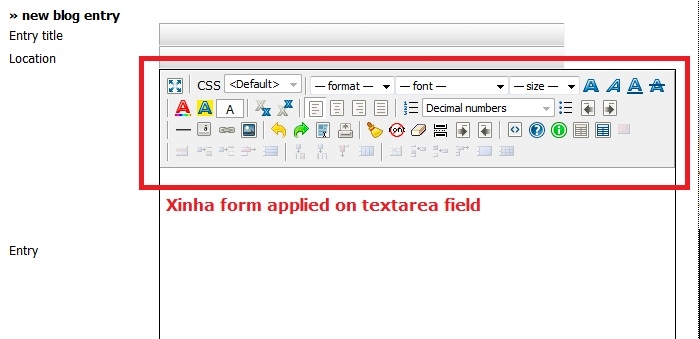
Although the Xinha project is old and probably dead (the last update dates from May 2010) it still is a very effective TextArea-Editor and easy to install.
There was only one issue which bugged me for a long time: Instead of writing <br> tags as linebreak, the XML version <br /> was always used.
This is fine if one has declared his page encoding with the XHTML standard but the W3C validator complains when the page's encoding is set to HTML 4.01.
Unfortunately there is no setting in Xinha to set the encoding output but it is manually possible to handle this problem.
In XinhaCore.js set the HTML output method from DOMwalk (default) to TransformInnerHTML:
/** This determines the method how the HTML output is generated.
* There are two choices:
*
*<table border="1">
* <tr>
* <td><em>DOMwalk</em></td>
* <td>This is the classic and proven method. It recusively traverses the DOM tree
* and builds the HTML string "from scratch". Tends to be a bit slow, especially in IE.</td>
* </tr>
* <tr>
* <td><em>TransformInnerHTML</em></td>
* <td>This method uses the JavaScript innerHTML property and relies on Regular Expressions to produce
* clean XHTML output. This method is much faster than the other one.</td>
* </tr>
* </table>
*
* Default: <code>"DOMwalk"</code>
*
* @type String
*/
this.getHtmlMethod = 'TransformInnerHTML';
Then in modules/GetHtml/TransformInnerHTML.js the replace(c[4] line needs to be commented-out. This code is responsible to forward-slash-close single tags:
Xinha.prototype.cleanHTML = function(sHtml) {
var c = Xinha.RegExpCache;
sHtml = sHtml.
replace(c[0], function(str) { return str.toLowerCase(); } ).//lowercase tags/attribute names
replace(c[1], ' ').//strip _moz attributes
replace(c[12], ' ').//strip contenteditable
replace(c[2], '="$2$4$5"$3').//add attribute quotes
replace(c[21], ' ').//strip empty attributes
replace(c[11], function(str, p1, p2) { return ' '+p1.toLowerCase()+p2; }).//lowercase attribute names
replace(c[3], '>').//strip singlet terminators
replace(c[9], '$1>').//trim whitespace
replace(c[5], '$1$3="$3"$5').//expand singlet attributes
//replace(c[4], '<$1$2 />').//terminate singlet tags
replace(c[4], '<$1$2>').//terminate singlet tags
replace(c[6], '$1$2').//check quote nesting
replace(c[7], '&').//expand query ampersands
replace(c[8], '<').//strip tagstart whitespace
replace(c[10], ' ');//trim extra whitespace
if(Xinha.is_ie && c[13].test(sHtml)) {
As you see, I commented-out the original line to terminate singlet tags and replaced it by the following line where the tag is closed without a forward-slash.
From now on Xinha will write <br> tags without the closing forward-slash.
No comments yet.

AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Zoneminder